
Multimodal machine learning (ML) represents a rapidly advancing frontier in artificial intelligence, focusing on the development of systems capable of processing, interpreting, and integrating information from diverse sensory modalities. These modalities include, but are not limited to, text, images, audio, video, and sensor data. By mimicking human cognitive processes that naturally combine various sensory inputs, multimodal AI aims to achieve a more comprehensive, robust, and context-aware understanding of the real world. This interdisciplinary domain moves beyond the limitations of unimodal analysis to foster more intelligent and versatile applications across numerous fields.
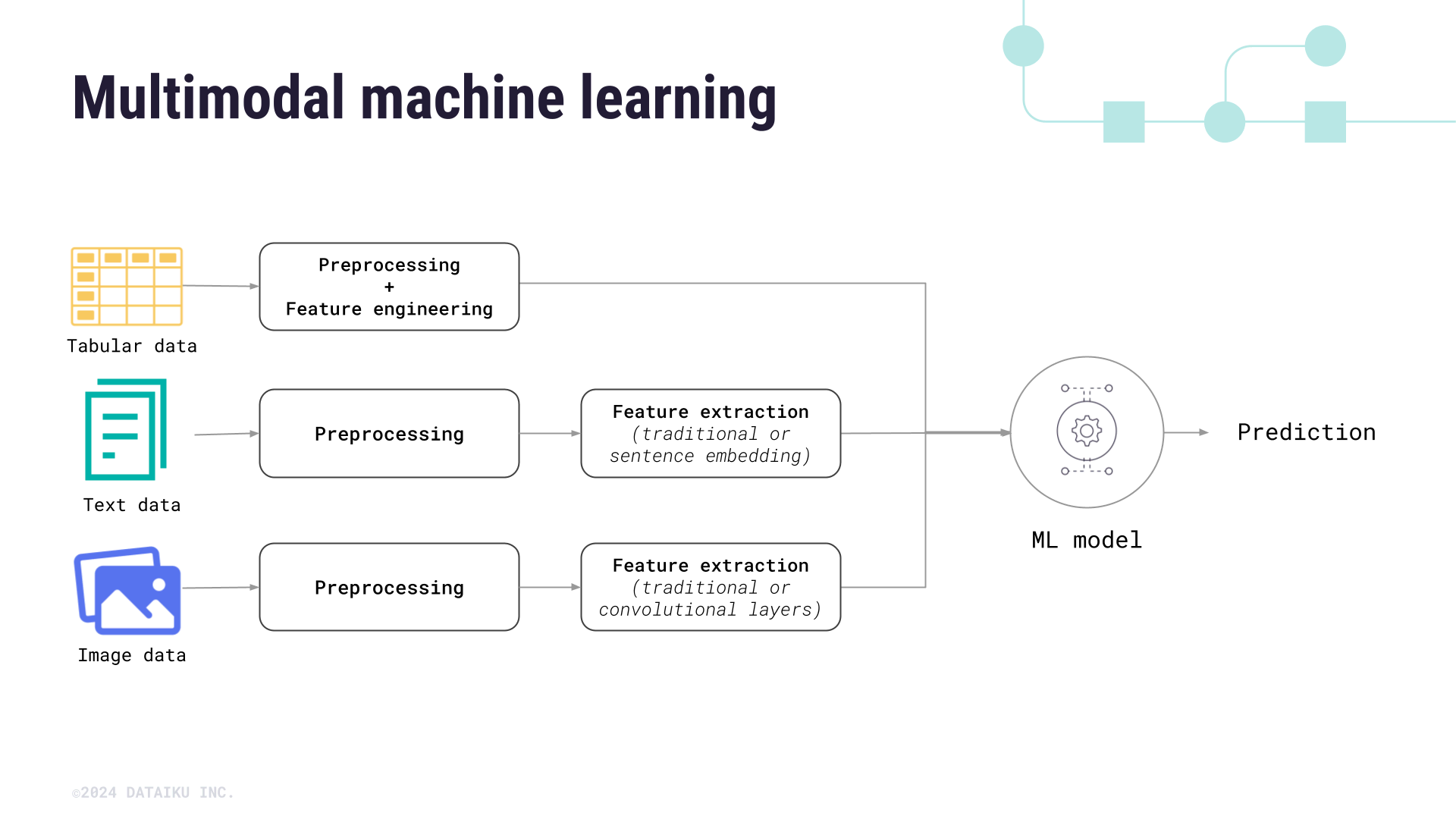
Figure 1: Illustration of various data modalities converging into an AI model for multimodal processing, highlighting the foundational concept of integrating diverse information streams.
A foundational challenge in multimodal ML revolves around effectively fusing information from these inherently heterogeneous sources. Early methodologies often employed early fusion, wherein raw data from different modalities were concatenated prior to being fed into a singular model. Conversely, late fusion approaches involved processing each modality independently with separate models, combining their outputs only at a subsequent stage for tasks like decision-making. Contemporary research increasingly emphasizes intermediate fusion or representation learning, which seeks to learn joint or coordinated representations that intrinsically capture the intricate relationships between modalities. This often entails embedding diverse modal data into a common latent space, facilitating seamless comparison and integration, as seen in the sophisticated architectures of modern multimodal large language models.
Figure 2: A conceptual model illustrating how a Multimodal Large Language Model (LLM) integrates various input modalities to generate diverse outputs, embodying advanced fusion techniques for richer understanding.
The emergence of transformer architectures has profoundly accelerated progress in multimodal learning, particularly in vision-language tasks. Models such as CLIP (Contrastive Language–Image Pre-training) [1] and ViLT (Vision-and-Language Transformer) [4] leverage sophisticated self-attention mechanisms to learn powerful cross-modal alignments. These models are typically trained on vast datasets of paired image-text instances, enabling them to associate visual concepts with their corresponding textual descriptions and vice versa. This capability forms the bedrock for a range of applications, including cross-modal retrieval, image captioning, and visual question answering, where models must jointly reason over visual content and linguistic queries. Architectures like FLAVA further exemplify this by employing distinct encoders for different modalities, followed by intricate cross-attention mechanisms to allow for deep interaction and integrated understanding across modalities [Figure 3].
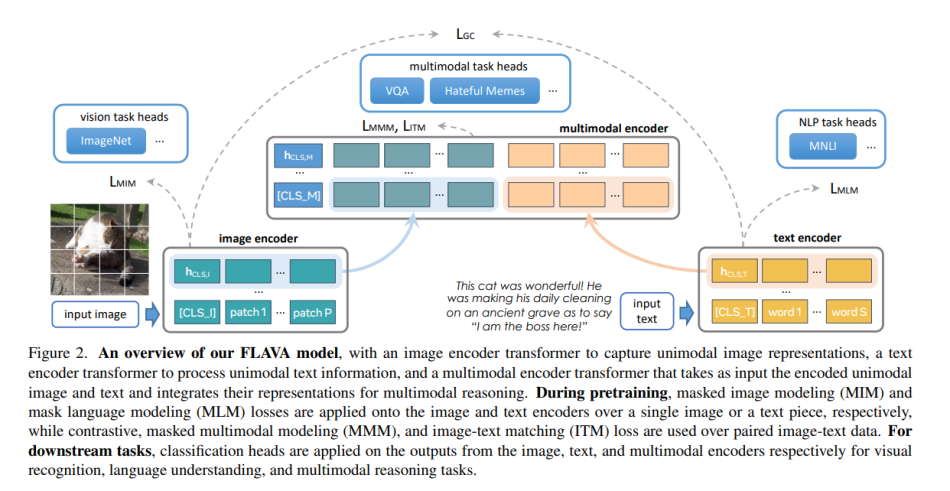
Figure 3: An example of a multimodal transformer architecture (Facebook FLAVA), depicting separate encoders for vision and language, followed by intricate cross-attention mechanisms for deep interaction and shared representation learning.
Beyond discriminative tasks, self-supervised learning and generative AI are making substantial contributions to the multimodal domain. Self-supervised learning allows models to extract rich representations from unlabeled multimodal data by constructing pretext tasks, such as predicting masked portions of one modality based on information from another. Generative multimodal models, exemplified by DALL-E [5] and Stable Diffusion, represent the cutting edge, demonstrating the ability to synthesize highly realistic images from textual descriptions or generate descriptive captions for complex visual scenes. These models showcase a deep understanding of how concepts are expressed across different modalities, opening novel avenues for creative AI and advanced content generation by integrating various strategies for learning and interaction [Figure 4].
Figure 4: A comprehensive guide to multimodal learning strategies, depicting the interplay of various input types, processing stages, and output modalities, which underpins the development of advanced generative and analytical models.
Despite these remarkable advancements, multimodal machine learning continues to grapple with several significant challenges. These include effectively handling missing modalities, ensuring accurate temporal synchronization for misaligned data (e.g., in video and audio streams), managing the inherent heterogeneity and high dimensionality of multimodal datasets, and enhancing the interpretability of complex multimodal interactions. Furthermore, developing scalable and robust graph-centric approaches for learning intricate relationships across modalities poses unique difficulties [Figure 5]. Nonetheless, the societal impact of multimodal AI is broad and transformative, with critical applications spanning robotics (for integrated perception and interaction), autonomous driving (integrating lidar, radar, and camera data), healthcare (diagnostics from medical images, patient notes, and sensor data) [3], and human-computer interaction (simultaneously understanding speech, gestures, and facial expressions). The future trajectory promises the development of more robust fusion techniques, improved generalization across novel modalities, and a deeper understanding of causal relationships within multimodal data.
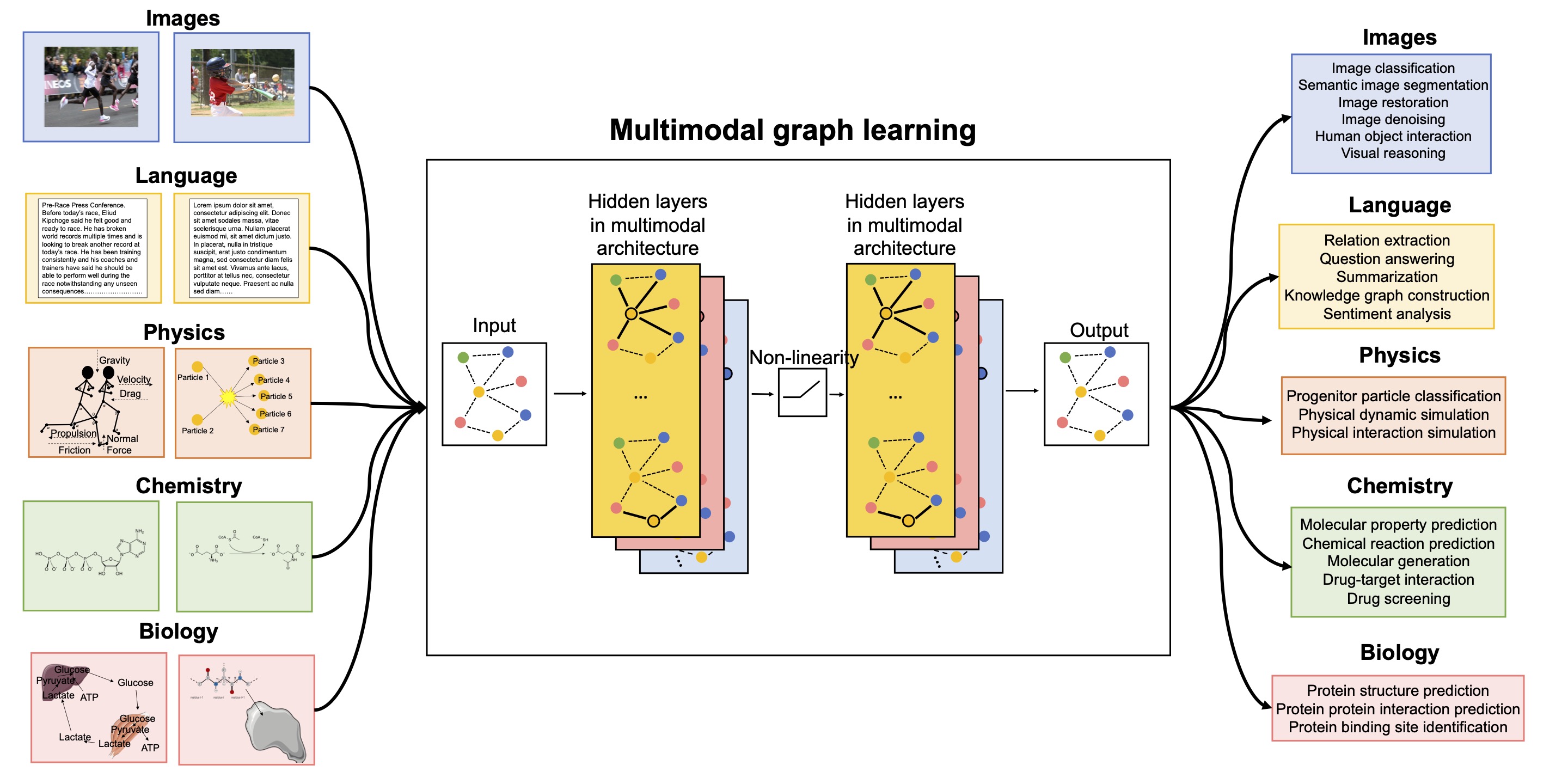
Figure 5: An overview of multimodal graph learning, showcasing how graph structures can represent complex relationships between different modalities, and underscoring the challenges in scaling and effectively utilizing such intricate networks.
Bibliography
- Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, et al. “Learning transferable visual models from natural language supervision.” In Proceedings of the International Conference on Machine Learning, 8748–8763. 2021.
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “BERT: Pre-training of deep bidirectional transformers for language understanding.” In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, vol. 1, 4171–4186. 2019.
- Li, Zhilong, and Liming Fu. “Multimodal deep learning for healthcare: A comprehensive review.” IEEE Journal of Biomedical and Health Informatics 27, no. 1 (January 2023): 111–125.
- Yu, Wonjae, Jong Ryul Lee, Byeonghyeon Kim, Youngjae Yu, Jonghyun Paik, Sumin Lee, and Moontae Lee. “ViLT: Vision-and-language transformer for visual-linguistic pre-training.” In Proceedings of the International Conference on Computer Vision, 11526–11537. 2021.
- Ramesh, Prafulla, Mohammad Pezeshki, Samira Mirzaeian, Aditya Ramesh, Gabriel Goh, Scott Gray, Chong Wang, et al. “Zero-shot text-to-image generation.” In Proceedings of the International Conference on Machine Learning, 8821–8831. 2021.
- Liang, Chiyu, R. P. B. Xu, and Eric P. Xing. “Multimodal deep learning.” IEEE Signal Processing Magazine 37, no. 2 (March 2020): 81–91.
Leave a Reply